Waste Inferences!

Back in the 1970’s, Caltech professor Carver Mead suggested that, given the implications of Moore’s Law (which he coined!), we should embrace the growing abundance of transistors and “waste” them. Computing power was becoming cheaper at an exponential rate, and what that meant was that we should work to create more powerful, flexible, and innovative designs, even if it meant that they seemed inefficient at first glance.
Just a couple weeks ago Ethan Mollick released a newsletter (What Just Happened, What is Happening Next) that started off with the line “The current best estimates of the rate of improvement in Large Language Models show capabilities doubling every 5 to 14 months”. Not only are LLMs getting more powerful at an incredible rate, but the costs of using them are decreasing at a similar pace.
While many things are different this generation, the implication of the exponential growth of computing power and reduction in cost remains the same. We should embrace it and use it to create more powerful, flexible, and innovative designs even if it means they seem inefficient at first glance. In other words, we should be “wasting inferences” – using the abundant computing power of LLMs and plummeting costs to experiment with novel applications and designs, even if they don’t seem optimally efficient initially.
Thin Wrappers
The main way to dismiss anything anyone was building on LLMs over the last year was “isn’t this just a thin wrapper on top of GPT4?”. My answer was always some variation of “Well isn’t Salesforce just a thin wrapper on top of a relational database?”. It wasn’t until I read Venkatesh Rao’s A Camera, Not an Engine that I realized I wasn’t taking that line of thinking far enough. In the newsletter, he makes the case that we should be thinking of these generative AI models more as a discovery rather than an invention. Jeff Bezos made a similar observation right around the same time.
If we think about these models as a discovery rather than an invention, building thin wrappers over them is exactly what should be done! So many useful things in our daily lives are thin wrappers on top of discoveries. Lightbulbs, toasters, and air conditioners are all just thin wrappers on top of electricity. Building wrappers that provide new interfaces and uses for discoveries are how they are able to make meaningful change in people’s lives. This principle applies not only to physical inventions but also to groundbreaking digital discoveries like LLMs.
Beyond Conversational
If your exposure to LLMs since the release of ChatGPT has been limited to various chatbots, you might find the comparison between LLMs and the discovery of electricity to be an exaggeration. However, the potential applications of LLMs extend far beyond conversational interfaces. Once you start building software with them, and you realize that what you have access to is a near-universal function of string to string, you start to grasp how transformative these things truly are.
Obie Fernandez wrote about this recently in his post The Future of Ruby and Rails in the Age of AI. In the post he describes a component he’s building for his AI-powered consultants platform Olympia and ends the section with “The internal API for this component is plain text. I’m literally taking what would have been dozens or hundreds of lines of code and letting AI handle the job in a black-box fashion. Already. Today.”
Things that previously would have required teams of people, taken multiple sprints, or even quarters worth of work, are now an API call away. Obie Fernandez’s example demonstrates how LLMs can significantly reduce development time and effort. As more developers recognize the potential of “wasting inferences” on innovative applications, we’ll likely see a surge in powerful, AI-driven solutions across many different domains.
Where To Start
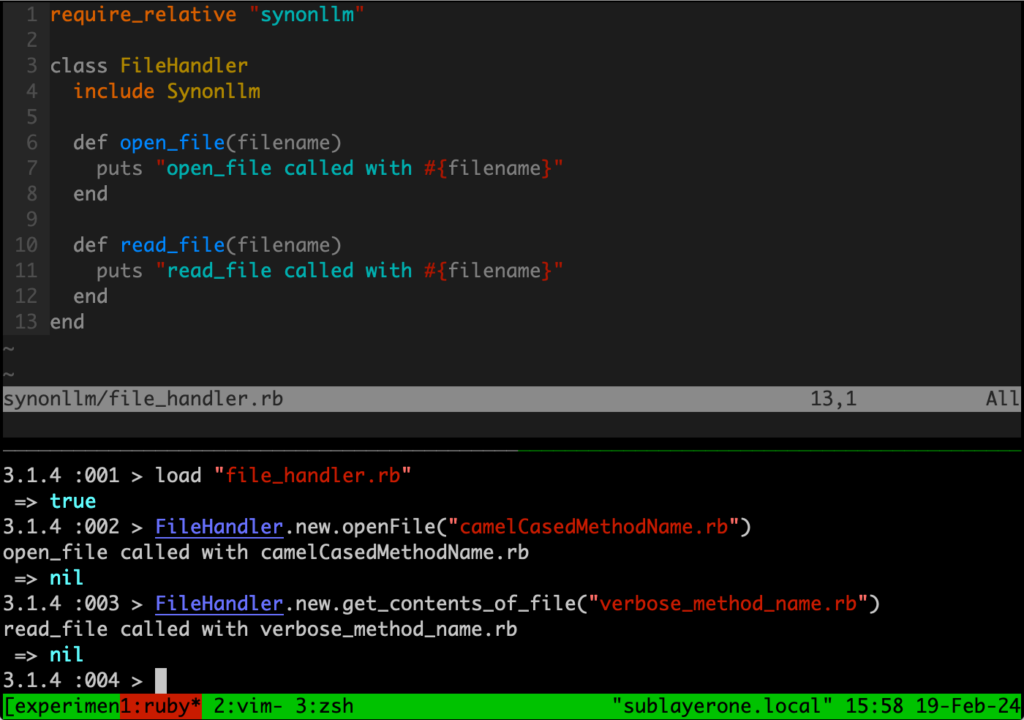
Ok so if you’re still with me, you may be thinking: “Where do I start? How can I waste inferences and make more thin wrappers?” Well I’m glad you asked! My recommendation is to start small. At Sublayer we’re building a Ruby AI framework that works with all available models to do just that.
At its simplest, the way you work with language models can be summed up as:
Gather information -> Send information to an LLM -> Do something with the LLM’s output
Our framework is designed to help you build programs with that flow as simply as possible, and we have tutorials up for how to build simple things like a TDD bot with an LLM writing code for you, a simple voice chat application in Rails, and coming soon, a tutorial for how we built CLAG, a command line program that generates command line commands for you with it. We’re constantly making new tutorials, so keep an eye out and let us know if there’s anything you build with it, we’d love to help spread the word!
These tutorials are just examples though. They’re meant to show how quickly you’re able to create new applications and “waste inferences” on powerful, flexible, and innovative things that may not seem the most efficient at first glance.
Make sure to also check out our docs site that has interactive code generation built right into it to make getting started even faster.
Learn More
Ready to learn more?
We spend most of our time in the Sublayer discord, so if you have questions, requests for more tutorials or features, and want to learn more about how to “waste inferences”, come join us! You’ll have the opportunity to collaborate with like-minded developers, get support for your projects, and stay up-to-date with the latest advancements in AI-powered development. We’d love to meet you and push the limits of what these models are capable of together!
There’s also a larger, more general community of Rubyists forming around AI that we’re a part of. Join the Ruby AI Builders discord to connect with developers who are exploring various applications of AI in the Ruby ecosystem. It’s a great place to exchange ideas, share your projects, and learn from the experiences of others
In a future post we’ll go into more details about why we think Ruby is a sleeping giant in the world of AI application development and is perfect for “Wasting Inferences”